
Η κατασκευή της βάσης δεδομένων πραγματοποιήθηκε σε τρεις φάσεις: (1) συλλογή δεδομένων από το Web of Science (WoS), (2) καθαρισμός και εξαγωγή δεδομένων (προεπεξεργασία) και (3) δημιουργία κόμβων δικτύου παραπομπών και πινάκων τερματικών. Το σχήμα 1 απεικονίζει το πλαίσιο δημιουργίας βάσης δεδομένων.
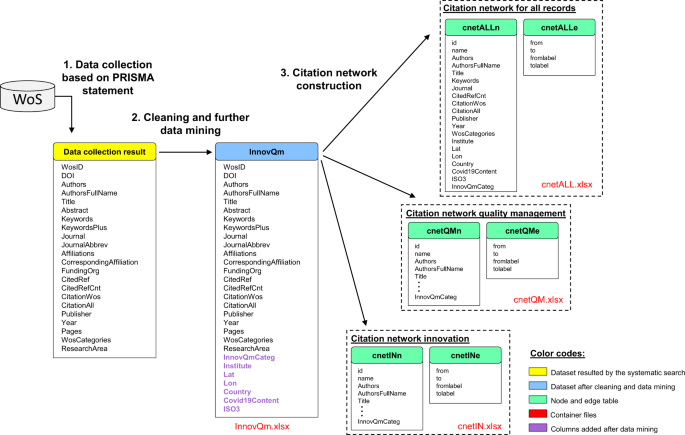
Πλαίσιο δημιουργίας βάσης δεδομένων.
Συλλογή δεδομένων
Η συλλογή δεδομένων πραγματοποιήθηκε με τη χρήση της μεθοδολογίας PRISMA που προτείνεται από20. Αυτή η μέθοδος παρέχει καθοδήγηση στους ερευνητές για τη διεξαγωγή συστηματικών ανασκοπήσεων της βιβλιογραφίας ακολουθώντας τα τέσσερα προτεινόμενα βήματα: (1) αναγνώριση, (2) έλεγχος, (3) καταλληλότητα και (4) συμπερίληψη. Η μεθοδολογία PRISMA επιλέχθηκε ως πλαίσιο συλλογής και φιλτραρίσματος δεδομένων λόγω των ακόλουθων πλεονεκτημάτων: παρέχει μια ολοκληρωμένη και διαφανή διαδικασία. Ισχύουν σε οποιοδήποτε ερευνητικό πεδίο. Υποστηρίζει σθεναρά την κλωνοποίηση ελέγχου. Επιπλέον, ένα διάγραμμα ροής διεργασιών (που αναφέρεται επίσης στο PRISMA) βοηθά τους αναγνώστες να κατανοήσουν καλύτερα τη συνολική διαδικασία και τους περιορισμούς της μελέτης και μπορεί να αυξήσει την ποιότητα της ανασκόπησης της βιβλιογραφίας.21. Η αναζήτηση πραγματοποιήθηκε χωριστά για τις δύο περιοχές ενδιαφέροντος και τα αποτελέσματα συνδυάστηκαν για να παρέχουν ολόκληρο το σύνολο βιβλιομετρικών δεδομένων. Το Σχήμα 2 απεικονίζει τη διαδικασία συλλογής δεδομένων.
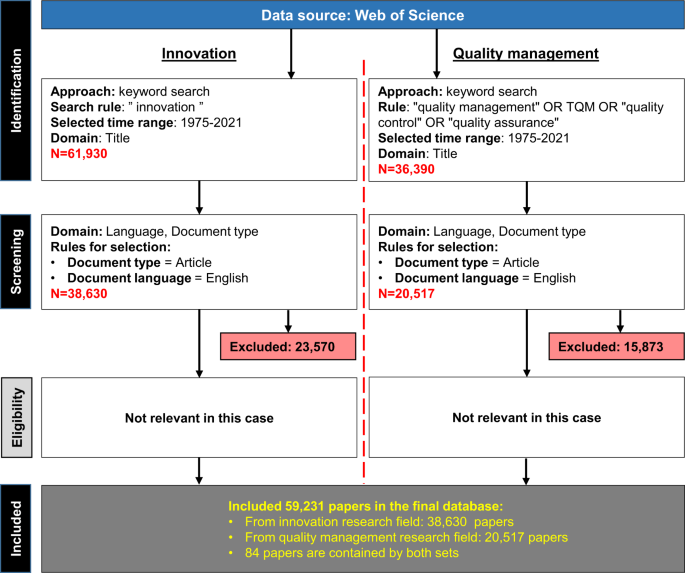
Η έρευνα λέξεων-κλειδιών χρησιμοποιήθηκε και στα δύο θέματα στην πλατφόρμα WoS. Η αναζήτηση πραγματοποιήθηκε μόνο σε τίτλους άρθρων για να μειωθεί η συμπερίληψη άσχετων εγγράφων που αναφέρουν μόνο όρους στην περίληψη που σχετίζονται με την καινοτομία ή τη διαχείριση ποιότητας. Ολόκληρο το εύρος ημερομηνιών αναλύθηκε (το πρώτο διαθέσιμο έτος στο WoS ήταν το 1975) μέχρι την ημερομηνία συλλογής δεδομένων, η οποία πραγματοποιήθηκε στις 22 Σεπτεμβρίου 2021. Όσον αφορά τη γλώσσα των εγγράφων, τα αγγλικά θεωρήθηκαν ως η γλώσσα για επιστημονική δημοσίευση22. Στην περίπτωση του τομέα καινοτομίας (αριστερή πλευρά του Σχήματος 2), βρέθηκαν 61.930 εγγραφές μετά από αναζήτηση λέξεων-κλειδιών στη δεδομένη χρονική περίοδο. Ο αριθμός αυτός μειώθηκε σε 38.630 μετά την εφαρμογή των παραπάνω κανόνων φιλτραρίσματος εξαιρουμένων των 23.570 χαρτιών. Στην περίπτωση της διαχείρισης ποιότητας (δεξιά πλευρά του Σχήματος 2), βρέθηκαν 36.390 ερευνητικές εργασίες με αναζήτηση λέξεων-κλειδιών και αυτός ο αριθμός μειώθηκε κατά τη φάση της εξέτασης σε 20.517 εξαιρουμένων των 15.873 εργασιών επειδή ήταν ή ήταν σε γλώσσα διαφορετική από την αγγλική. Άλλοι τύποι άρθρων. Σε αυτό το έγγραφο, το βήμα «επιλεξιμότητας» είναι άσχετο επειδή ο αριθμός των εγγραφών δεδομένων που δημιουργούνται δεν καθιστά δυνατή τη μη αυτόματη ανάγνωση και αξιολόγηση όλων των εγγράφων που εξετάστηκαν και αξιολογήθηκαν. Μετά την εφαρμογή των βημάτων που προτείνονται από τη μεθοδολογία PRISMA, συλλέχθηκαν στη βάση δεδομένων 59.231 εργασίες που εξετάστηκαν.
Καθαρισμός και εξόρυξη δεδομένων
Ο στόχος αυτού του βήματος ήταν να επεκταθεί το σύνολο δεδομένων με πρόσθετες μεταβλητές αξίας, όπως το ινστιτούτο πρώτου συγγραφέα, η χώρα του πρώτου συγγραφέα, ο κωδικός χώρας ISO3, το περιεχόμενο COVID-19, οι γεωγραφικές συντεταγμένες και ο θεματικός δείκτης (καινοτομία ή διαχείριση ποιότητας). Πρόσθετες παραλλαγές εισήχθησαν με βάση τα ακόλουθα:
Ινστιτούτο Πρώτου Συγγραφέα (Το Ινστιτούτο)
στήλη “δεσμεύσειςΑυτά τα δεδομένα αποθηκεύτηκαν αρχικά ως μια συνέχεια που περιελάμβανε όλα τα ονόματα και τις συσχετίσεις των δημιουργών. Ένα άλλο πρόβλημα ήταν ότι οι ίδιοι συντάκτες της ίδιας σχέσης αντιμετωπίζονταν ως μια ενιαία οντότητα στην αλυσίδα και οι σύνδεσμοί τους δεν ακολουθούσαν την ίδια μορφή και δομή στο All περιπτώσεις. Λόγω αυτής της μη δομημένης φύσης, η εκκαθάριση κειμένου και η εξαγωγή κειμένου θα πρέπει να χρησιμοποιηθούν για την εξαγωγή των απαιτούμενων πληροφοριών. Για να επιστρέψετε τη σχέση του πρώτου συγγραφέα, πρώτα χρησιμοποιήθηκαν κανονικές εκφράσεις για την αφαίρεση περιττών υποσυμβολοσειρών· δεύτερον, οι συντμήσεις του όρου αντικαταστάθηκαν με τις πλήρεις μορφές τους (όπως “”Πανεπιστήμιο” αντί “Πανεπιστήμιο. “ή”Διαίρεση” αντί “Διαίρεση. Τέλος, η καθαρισμένη συμβολοσειρά κωδικοποιήθηκε για να διαχωρίσει συγκεκριμένα μέρη της συνεργασίας, όπως το όνομα του ιδρύματος, την πόλη, τη διεύθυνση δρόμου και τη χώρα. Αυτά τα βήματα εκτελέστηκαν χρησιμοποιώντας το σενάριο Python.
Στήλες που σχετίζονται με τη χώρα (Χώρα, ISO3)
χρησιμοποιώντας την προεπεξεργασμένη στήλη”ινστιτούτο“, η χώρα υπαγωγής του πρώτου συγγραφέα εξήχθη ως μέρος της καθαρής συμβολοσειράς. Δεν εξήχθησαν μόνο τα ονόματα των χωρών, αλλά εκχωρήθηκαν οι κωδικοί ISO3 τους. Επειδή πολλά προγράμματα και στατιστικά πακέτα (όπως το R) προσδιορίζουν τις χώρες με βάση Κώδικες ISO, αυτό το βήμα καθιστά εύκολη τη μάθηση για τα στατιστικά πακέτα χωρίς την ανάγκη περαιτέρω προσπαθειών προγραμματισμού από την πλευρά του ερευνητή.
Περιεχόμενο COVID-19 (@Covid19Content)
Για να επισημανθεί εάν η εργασία γράφτηκε στο πλαίσιο του COVID-19, χρησιμοποιήθηκε αναζήτηση λέξεων-κλειδιών και η τιμή της στήλης ορίστηκε σε 1 εάν ο τίτλος, οι λέξεις-κλειδιά ή η περίληψη περιείχαν τουλάχιστον μία από τις ακόλουθες λέξεις-κλειδιά:Νόσος κορωνοϊού“,”Κορωνοϊός“,”πανδημία“, ή”SARS-CoV-2Διαφορετικά, η τιμή του ορίζεται στο μηδέν.
Γεωγραφικές συντεταγμένες (lat, χρώμα)
Οι τιμές γεωγραφικού μήκους και γεωγραφικού πλάτους που σχετίζονται με τη συσχέτιση του πρώτου συγγραφέα ανακτήθηκαν με γεωκωδικοποίηση χρησιμοποιώντας GeoPy Πακέτο Python. Η γεωκωδικοποίηση πραγματοποιήθηκε χρησιμοποιώντας την εξαγόμενη και κωδικοποιημένη στήλη «Ίδρυμα» ως τιμές εισόδου.
Δείκτης κατηγορίας αναζήτησης (InnovQMCateg)
Αυτή η στήλη προστέθηκε με μη αυτόματο τρόπο κατά τον συνδυασμό των αποτελεσμάτων από τις δύο αναζητήσεις, όπως φαίνεται στο Σχήμα 2. Εάν ένα συγκεκριμένο έγγραφο είχε συλλεχθεί αποκλειστικά από έρευνα που σχετίζεται με την καινοτομία, η τιμή του ορίστηκε σε «Συνεργασίαόνομα τάξης”Ποιότητα“Δηλώνει ότι το χαρτί μπορεί να βρεθεί αποκλειστικά στα αποτελέσματα αναζήτησης διαχείρισης ποιότητας. Τέλος, ο σταυρός αναφέρεται ως κατηγορία”Και τα δυοΣε αυτήν την περίπτωση, οι διπλότυπες εγγραφές έχουν αφαιρεθεί από το υπολογιστικό φύλλο.
Χτίζοντας ένα μαρτυρικό δίκτυο
Οι πίνακες κόμβων και ακμών δημιουργήθηκαν χρησιμοποιώντας το σύνολο δεδομένων που συλλέχτηκε και υποβλήθηκε σε περαιτέρω επεξεργασία από το WoS. Στο κύριο σύνολο δεδομένων, τα αναφερόμενα άρθρα αποθηκεύτηκαν σε μία στήλη σε μορφή συμβολοσειράς. Για να δημιουργήσετε μια μορφή λίστας ακμών από μια μεταβλητή εισόδου τύπου συμβολοσειράς, εφαρμόστηκαν εντολές RegEx (κανονικές εκφράσεις) για την εύρεση όλων των αριθμών DOI που εμφανίζονται μέσα στο μεγάλο κείμενο. Μετά την εξαγωγή των εν λόγω αριθμών DOI, δημιουργήθηκε μια μορφή λίστας. Η διαδικασία δημιουργίας μιας λίστας ακμών μπορεί να περιγραφεί ως εξής:
-
1.
επιλέξτε χαρτί Εγώ
-
2.
Εξαγάγετε όλους τους αριθμούς DOI από τη συμβολοσειρά αναφοράς που αναφέρεται χρησιμοποιώντας κανονικές εκφράσεις
-
3.
Για όλους τους αριθμούς DOI που εξήχθησαν: προσθέστε DOIΕγώ – DOIy λίστα ζευγαριών στην άκρη (όπου y Εσυ yΤο δέκατο Ένα στοιχείο DOI που εξάγεται για χαρτί Εγώ)
-
4.
Επαναλάβετε τα βήματα 1 έως 3 για όλα τα φύλλα (DOI) εντός του υποκείμενου συνόλου δεδομένων.
Η κατασκευή έγινε σε Python χρησιμοποιώντας επαναλαμβάνωΚαι το NLTKΚαι το αριθμός Και το αρκτοειδές ζώο της ασίας πακέτα.

“Ερασιτέχνης διοργανωτής. Εξαιρετικά ταπεινός web maven. Ειδικός κοινωνικών μέσων Wannabe. Δημιουργός. Thinker.”


